
Ignoring all the OpenAI drama, I’ve been playing with Chat GPT and custom GPTs more. This one started last spring when I tried to make a version of it run locally with some success.
The idea is to take the open-sourced climbing info from OpenBeta and train a chatbot on it. This presents the opportunity to easily see info across different climbing spots, or even across states (or countries). You could use it to find the best concentration of climbs at a certain level or customize a rack for an area based on what people say.
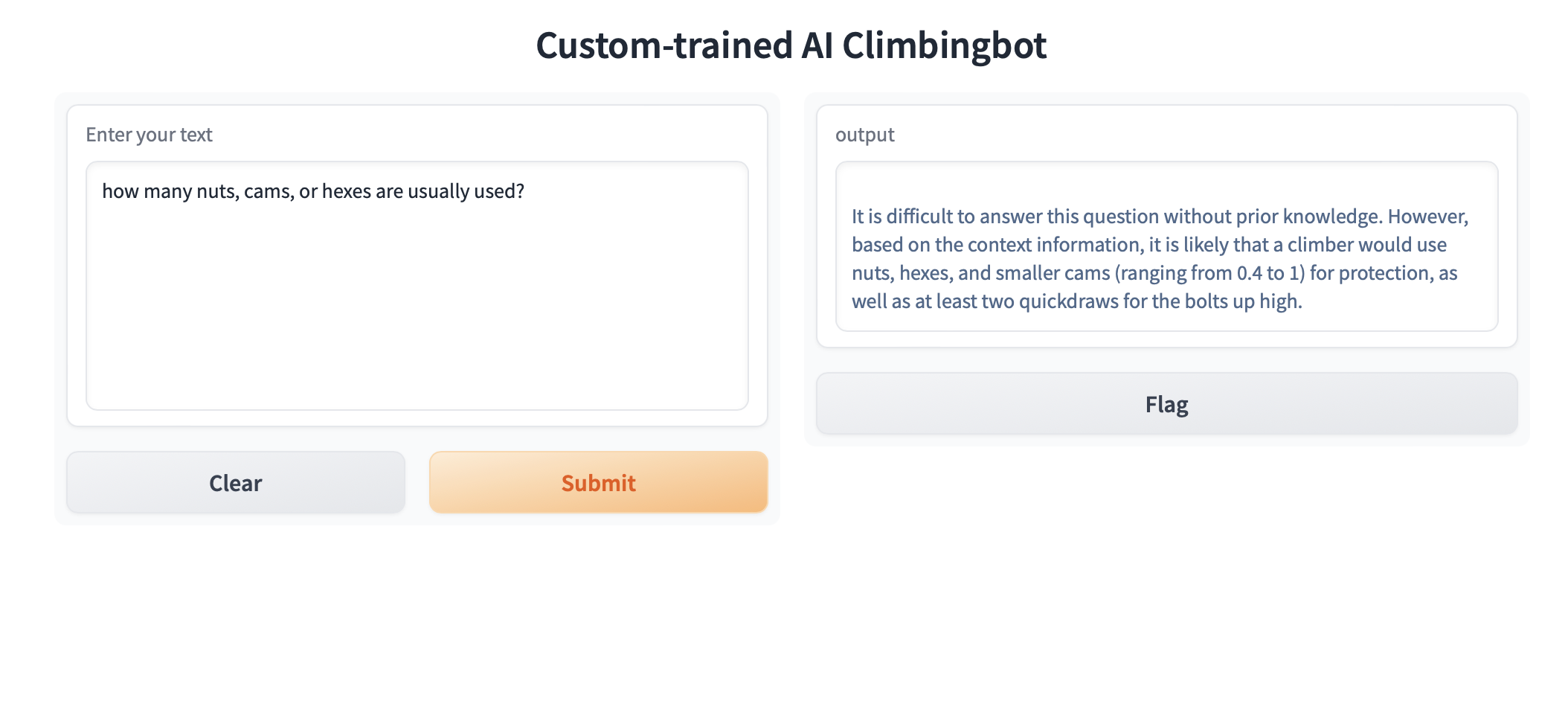
My first try was in the spring, running it locally with GPT3.5. By necessity I limited the data to MN it was a medium amount of data, and because it’s my home state I could verify the answers easily. This worked pretty well, but the limitations of 3.5 and the data set made it marginally useful.
Fast forward to custom GPTs with 4 and things are a bit better. First I was able to expand the data set to the entire US, and the data overall is more detailed. Second ChatGPT now is so much better than it was a few months ago. It finds things better even in a pretty large multi-directory file, and it hallucinates less. You get pretty useful answers from the new version.
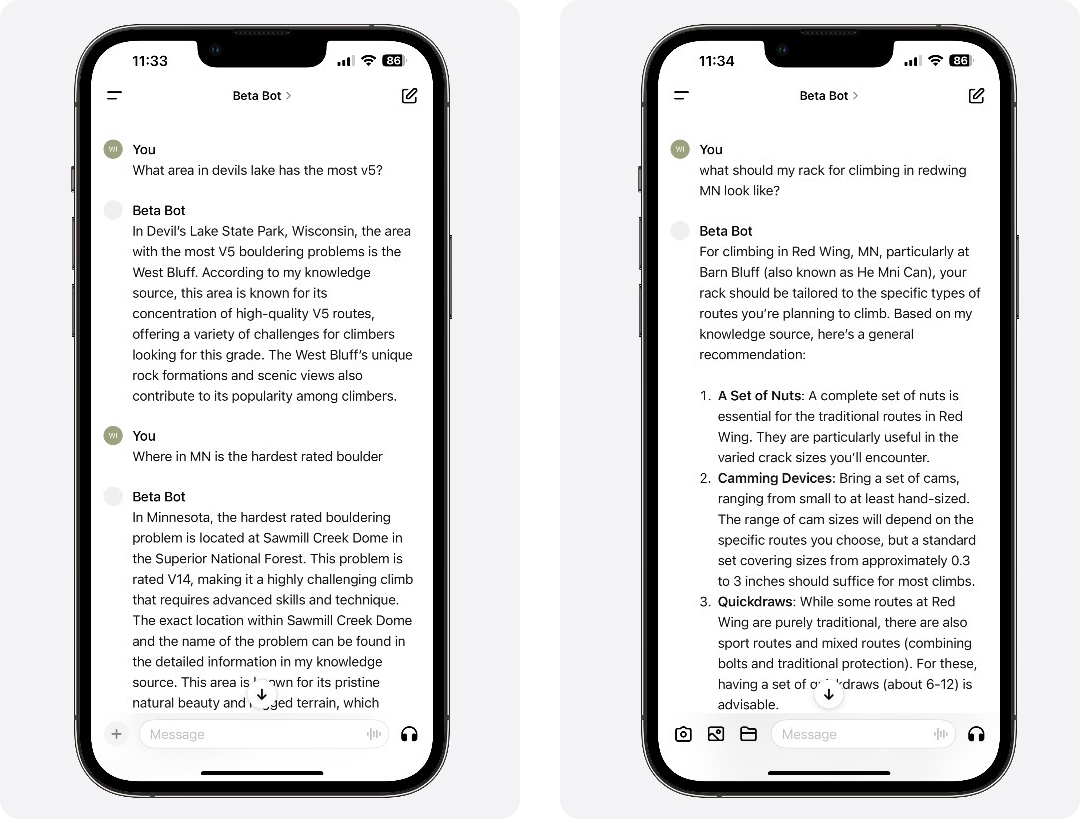
The answers are good (this is a data problem) L' Étoile du Nord is the correct answer to the hardest boulder question (video here)
So What Am I Learning?
Your data source is super important. Quality of data isn’t unique to Generative AI and LLMs but it is nonetheless super important. The structure of the data is more important than the consistency. As long as the model knows how to “read” the data it can draw inferences. Part of the problems with the current version of Beta Bot is the messiness of the OpenBeta data.
Designing for outside consequences is vital. The tone of a chatbot and the way the interface works creates a feeling of expertise in the bot. This makes it essential to think about what kind of advice it will give. For example in one session it recommended a handful of climbs at Swede’s Forest in MN, but Swede’s forest is closed to climbing and has been for years. Because it feels like your getting recommendations from an expert, someone might not even think about it. Looking for these real world error states and preventing them is key to avoiding bad consequences.
Training for clarity is another important consideration. It’s very possible to be asking a chatbot questions about one location and have it answer about a different location because they names were really close (or identical). Train in loops not just to clarify, but ensure that clarity is included in answers, adding the grade and state might make it more verbose, but ensuring clarity is worth it.
I’m going to write more on this in the future but there is an entire class of guides out there (digital and physical) that need to be looking at this. Often they are too detailed or too general. It’s hard to plan a trip when you have a detailed guide that goes over every aspect, it’s too much. Conversely once you decided on specifics an overview is not enough. LLM’s have the ability to fill both roles in a more natural way. They can help you narrow down options more quickly and accurately, and once you have decided on some specifics they can point you in the right direction for specifics.
So give Beta Bot a test. Like is said it’s still in progress and an experiment. So test it break it, send me some feedback. I’d love to learn.